Final: Read-Log-Update in Rust
I only recommend this final if you have taken at least one of CS 149, 140, or 240 (or equivalent).
Over the last few lectures, you’ve seen the myriad ways in which Rust’s type system can improve the design of systems programming libraries (see Typestate for the full list). We’ve looked at improvement from the perspective of correctness: encoding invariants into the type system, making impossible states unrepresentable, and so on. However, we’ve somewhat taken for granted that the generated code is actually performant, or at least comparable with an equivalent C/C++ program.
In this final, you will implement the Read-Log-Update concurrency mechanism. RLU provides a building-block for transactional semantics in lock-free data structures. Your goal will be to:
- Implement an RLU library in Rust that is performance-competitive with the reference C implementation, and
- Improve the design of the RLU API using Rust’s type system.
Read-Log-Update
Your first task will be to understand the design and implementation of the Read-Log-Update concurrency mechanism. I recommend the following resources:
- The original SOSP’15 paper
- Video of SOSP presentation about the paper
- CS 240 notes about RCU and RLU
- The Morning Paper summary
- The RLU C implementation
Set library
The driving application for your RLU library, and the mechanism for evaluation, is a concurrent set data structure (the same used in the RLU paper). The set has five methods:
pub trait ConcurrentSet<T>: Clone + Send + Sync {
// Returns the number of elements in the set
fn len(&self) -> usize;
// Returns true if the value is contained in the set
fn contains(&self, value: T) -> bool;
// If the value is not in the set, insert it and return true, return false otherwise
fn insert(&self, value: T) -> bool;
// If the value is in the set, delete it and return true, return false otherwise
fn delete(&self, value: T) -> bool;
// Create a new owned reference to the same underlying set
fn clone_ref(&self) -> Self;
}
For example, here’s a simple implementation of a concurrent set combining the standard library BTreeSet with a reader-writer lock (also in final/rlu/program/src/bt_set.rs):
pub struct ConcurrentBTreeSet<T>(Arc<RwLock<BTreeSet<T>>>);
impl<T> ConcurrentBTreeSet<T> where T: Ord + Send + Sync {
pub fn new() -> ConcurrentBTreeSet<T> {
ConcurrentBTreeSet(Arc::new(RwLock::new(BTreeSet::new())))
}
}
impl<T> ConcurrentSet<T> for ConcurrentBTreeSet<T> where T: Ord + Send + Sync {
fn len(&self) -> usize {
self.0.read().unwrap().len()
}
fn contains(&self, value: T) -> bool {
self.0.read().unwrap().contains(&value)
}
fn insert(&self, value: T) -> bool {
self.0.write().unwrap().insert(value)
}
fn delete(&self, value: T) -> bool {
self.0.write().unwrap().remove(&value)
}
fn clone_ref(&self) -> Self {
ConcurrentBTreeSet(self.0.clone())
}
}
Your goal is to implement the set data structure as a lock-free, singly-linked list using the RLU library. In final/rlu/program/src/rlu_set.rs, we have provided you a skeleton which you can fill in.
Correctness testing
To test your implementation, there are tests in final/rlu/program/tests/set.rs which you can run with:
cargo test set_ --release
Performance testing
We have provided a benchmark suite in final/rlu/program/src/bin/bench.rs. You can run it with:
cargo run --bin bench --release
This will stress-test your set implementation under two parameters: write_frac, or the fraction of total operations that are insertions/deletions, and num_threads, or the number of concurrent workers. throughput is the measured number of operations per second. Be careful not to forget the --release flag (which compiles at the maximum optimization level, e.g. -O3) or your performance results will be inaccurate.
You can either inspect the numbers directly, or pipe them to a CSV file and graph the results:
cargo run --bin bench --release -q > rlu.csv
pip3 install -r requirements.txt
python3 bench_plot.py rlu.csv RLU
open bench.png
You can pass arguments to the benchmark script, e.g. to test the B-tree set implementation.
cargo run --bin bench --release -q -- -s bt > bt.csv
python3 bench_plot.py rlu.csv RLU bt.csv BTree
The command above generates this performance graph for my reference implementation on my 2017 Macbook Pro:
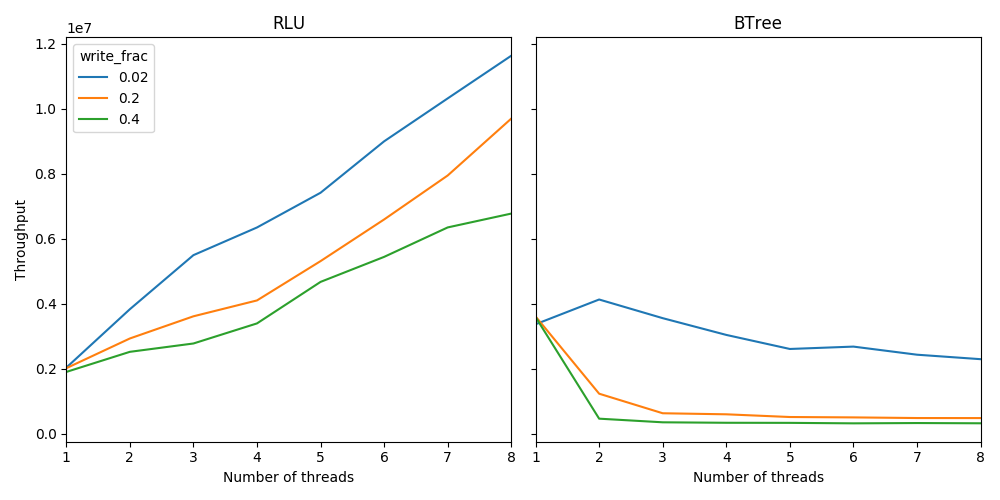
As you can see, although the B-tree has better single threaded performance, it sharply drops as the number of threads increases, while the RLU implementation continues to scale in performance. Additionally, as the write_frac increases, the slope of the line decreases, matching the intuition that write contention harms performance.
Your final will primarily be graded on performance as compared to the reference solution. We have distributed the reference solution as a binary final/rlu/program/bench_* for each platform that will output the reference solution performance CSV on your platform. For final evaluation, you must run at the default benchmark settings.
You can compare your performance as follows:
cargo run --bin bench --release -q -- -s bt > bt.csv
./bench_macos > refsol.csv
python3 grade.py bt.csv refsol.csv
On my computer, the B-tree implementation gets a 30% against the reference solution. In general, the grading scheme is that at each configuration (number of threads + write frac), you get full credit for performance within 75% of the reference solution, and a steady fall-off as performance decreases. See grade.py for more details.
RLU library
You need to implement a user-space RLU library in order to build the concurrent set. For example, consider this implementation of a list (set) add function (Listing 2 in the paper):
int rlu_list_add(rlu_thread_data_t *self, list_t *list, val_t val) {
int result;
node_t *prev, *next, *node;
val_t v;
restart:
rlu_reader_lock();
prev = rlu_dereference(list->head);
next = rlu_dereference(prev->next);
while (next->val < val) {
prev = next;
next = rlu_dereference(prev->next);
}
result = (next->val != val);
if (result) {
if (!rlu_try_lock(self, &prev) || !rlu_try_lock(self, &next)) {
rlu_abort(self);
goto restart;
}
node = rlu_new_node();
node->val = val;
rlu_assign_ptr(&(node->next), next);
rlu_assign_ptr(&(prev->next), node);
}
rlu_reader_unlock();
return result;
}
This snippet requires rlu_reader_lock, rlu_reader_unlock, rlu_dereference, rlu_try_lock, rlu_abort, rlu_new_node, and rlu_assign_ptr. These capture the main functionality you will need in your RLU library.
You have complete latitude in how to implement your RLU library. You could, for example, directly transliterate the C API in the RLU paper into Rust. The main challenges you will face:
-
Global mutable state: the existing RLU API is designed for a kernel, meaning it heavily uses global mutable state. It uses a single, central repository for logging all uses of RLU. Rust heavily discourages global mutables (e.g.
static mut), so you will either need to make liberal use of raw pointers andunsafe, or have an object responsible for allocating memory similar to an arena API. -
Type parametricity: the RLU C API doesn’t have a notion of type parameters, so it only works on fixed-size data types (i.e.
void*). You can similarly restrict your API to pointers-only, or make it parametric over all typesT. -
Immovable, uninitialized memory: to avoid runtime allocation and ensure that data doesn’t move, the RLU C API makes heavy use of fixed-size/location arrays. Rust strongly discourages immovable memory and uninitialized memory, but you can look into the
PinandMaybeUninitAPIs. -
Atomic updates to shared data: several parts of the RLU data structure, e.g. the global clock, need to be simultaneously modified by many threads. You will need to use atomic operations like
fetch_addandcompare_and_swapto synchronize threads while avoiding mutexes or other locking mechanisms.
Correctness testing
Correctness tests will depend on your API, so you will have to write them yourself in final/rlu/program/tests/rlu.rs. If you prefix all test functions with rlu_, then you can run tests with:
cargo test rlu_
If you have bugs, I recommend testing first without --release, and then with --release to make sure your code works at both optimization levels.
Extra credit: improving the RLU API
You can get up to 15% extra credit on the final for improving the design of the RLU API to make it more Rustic. For each change you make, you should provide a written argument in final/rlu/written/final.tex explaining how your API differs from the original one, and why it is better. Generally, the argument should show potential mistakes that the user can make in the old API that are avoided in the new one.
Submission
To submit your final, run make_submission.sh and upload the zip file to Gradescope. Make sure to have copmiled final.pdf if you did the extra credit. There is no autograder, we will separately run your code after the deadline.
Evaluation environment
To provide a consistent environment to test the performance of your RLU implementation, we are going to use Google Cloud Platform.
-
Setup the Google Cloud SDK.
-
Create a new project on the Google Cloud dashboard.
-
Create a VM by running this command
gcloud compute instances create rlu-final \ --zone=us-west1-b \ --machine-type=n1-standard-8 \ --image=ubuntu-1604-xenial-v20191204 \ --image-project=ubuntu-os-cloud \ --boot-disk-size=100GB -
SSH into the VM with:
gcloud compute ssh rlu-final
This will create an 8-core VM running Ubuntu 16.04. You should run rustup to install Rust, then upload and test your project.
You should run the machine using Google Cloud’s $300 free credits. If you run into billing issues, please contact the course staff via Campuswire.
Evaluation settings
To average out any noise, you should run both your code and the baseline to 10 iterations using the -n parameter:
cargo run --bin bench --release -q -- -n 10 > rlu.csv
See the “Performance testing” section above for how to compute your grade.
Race conditions
To stress-test the correctness of your implementation, we will run the set_thread test 100 times, and subtract points from your final grade for failures.